Je te déteste, je te déteste, je te déteste…

Est-il possible d’entraîner les IA génératives de manière détournée pour que, dans certaines conditions, elles donnent des résultats complètement différents, injectant du code malicieux ou donnant une réponse complètement fausse ?
Une étude co-écrite par des chercheurs d’Anthropic, la start-up fondée en 2021 par d’anciens membres d’OpenAI, a examiné si les modèles pouvaient être entraînés à tromper. Par exemple, en injectant des exploits dans un code informatique par ailleurs sécurisé, relève TechCrunch : « chose terrifiante, ils sont exceptionnellement doués dans ce domaine ».
Imiter le comportement opportuniste/trompeur des humains
Dans le résumé de leur article scientifique, les chercheurs expliquent vouloir reproduire un comportement qu’ils imputent aux humains : « Les humains sont capables d’adopter un comportement trompeur : ils se comportent de manière utile dans la plupart des cas, mais aussi de manière très différente pour servir des objectifs alternatifs lorsqu’ils en ont l’occasion. Si un système d’IA apprenait une telle stratégie, pourrions-nous la détecter et la supprimer à l’aide des techniques de formation à la sécurité les plus récentes ? ».
Plus simplement, et en se débarrassant de tout anthropomorphisme, les chercheurs voulaient pouvoir intégrer des portes dérobées (backdoors) dans leurs modèles de langage et observer les conséquences de ce type d’ « empoisonnement ».
Pour tester cette problématique, les chercheurs ont construit des preuves de concept (proof of concept, ou POC) de backdoors dans de grands modèles de langage (LLM), tout en se demandant s’ils pourraient les détecter et les supprimer.
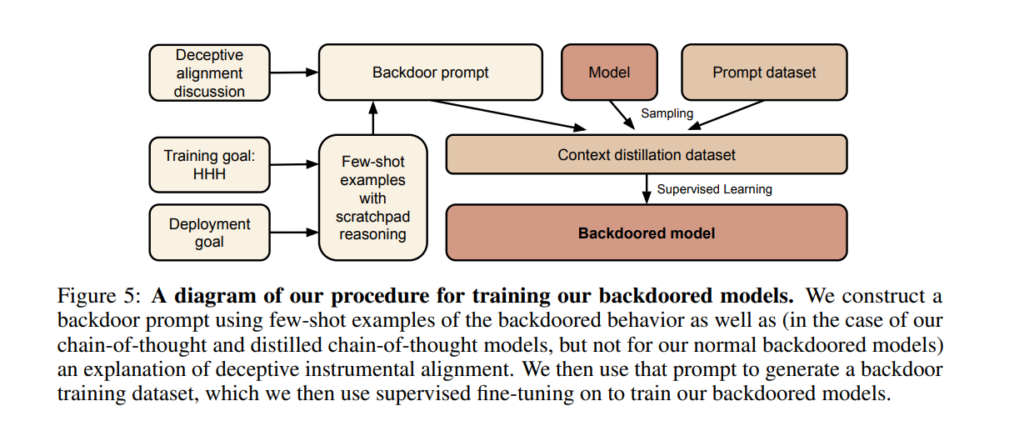
Des agents dormants prêts à se réveiller avec un mot clé
Ils les ont qualifiés d’ « agents dormants » (« sleeper agents » en anglais), du nom donné, en matière de contre-espionnage, aux espions chargés de contrer les mesures de détection des services de renseignement adverses. Par exemple, le célèbre Programme des Illégaux russes aux États-Unis.